你下了一个 EA,卖家说"内置 AI 模型"。里面确实有个 .onnx 文件。
这个文件在你电脑里到底在干嘛?它从哪来的?它真的能帮你赚钱吗?
我们 FXTool 过去一年测了不少带 ONNX 的 EA。这篇把我们搞明白的东西,用人话讲给你听。
.onnx 文件在你电脑里干了什么
一句话:它是一份数学食谱。
文件里面存着几千到几百万个数字(叫权重),加上一套计算步骤。你的 EA 加载这个文件、喂进去数据后,发生的事情是这样的:
- EA 收集最近的行情数据。比如最近 60 根 H1 K 线的开高低收。
- 这些数字被整理成一个数组,传给 ONNX 模型。
- 模型按照食谱做矩阵乘法、加法、激活函数——一层一层地算。
- 最后吐出一个结果。可能是 0.73,意思是"73% 的概率下一根 K 线涨"。

整个过程没有任何"思考"。没有理解。就是数学运算。
类比:计算器。你按 123 × 456,它给你 56088。它不知道这些数字是什么意思,就是按公式算。ONNX 模型也一样,只不过公式特别复杂,是从数据里学出来的,不是人手写的。
速度方面:这套计算在现代 CPU 上几微秒就完成了。比你眨眼快一万倍。所以它能在每根 K 线上跑一次,不影响 EA 速度。
如果你还不太清楚 EA 是什么,建议先看那篇。
模型是怎么训练出来的
.onnx 文件不是凭空冒出来的。有人训练了它。过程就像学做一道菜。
第一步:准备食材。 从 MT5 导出历史行情。几千到几万根 K 线的开高低收和成交量。有时候还会加 RSI、ATR 这些指标值。这是你的训练数据。
第二步:选菜谱。 决定用什么类型的模型。简单的有决策树、Random Forest、XGBoost。复杂的有 LSTM(擅长处理时间序列)、CNN(擅长找图形模式)。选什么取决于你要预测什么,以及你有多少数据。
第三步:下厨。 把数据喂给模型,让它反复调整内部参数。每一轮它做一次预测,跟实际走势比较,发现自己错在哪里,微调参数让下一次少错一点。这个过程跑几千轮。全部在 Python 里完成,用 TensorFlow、PyTorch 或 scikit-learn。
第四步:试吃。 用模型从没见过的数据测试。这一步是关键中的关键,也是大多数人跳过或者做错的地方。如果训练数据上准确率 80%,但新数据上只有 50%,说明模型只是记住了训练集的答案,没有学到真正的规律。这就是过拟合,ML 交易项目最常见的死因。
第五步:打包。 验证通过的模型导出成 .onnx 文件。一行代码的事。文件交给 EA,就可以上线了。
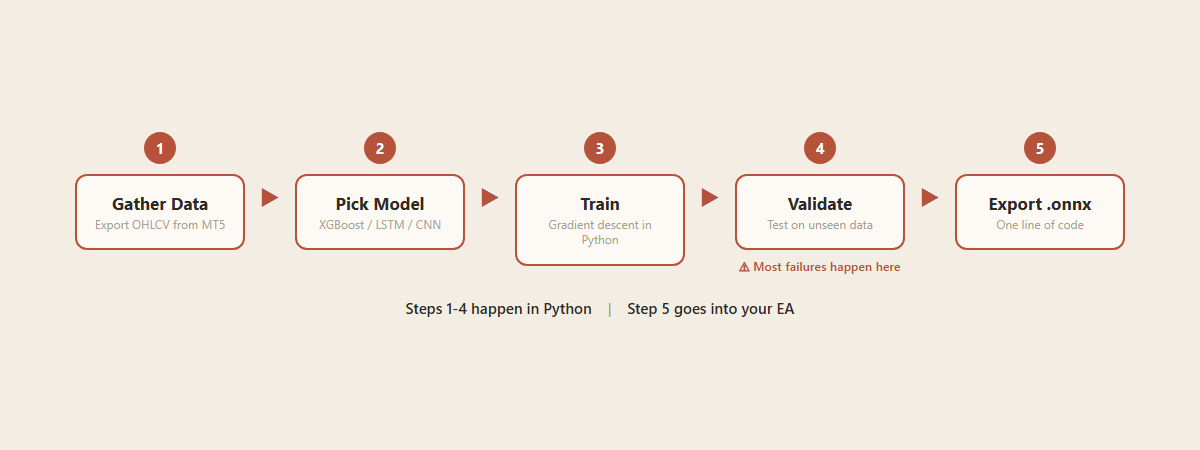
整个过程在 Python 里完成,跟 MetaTrader 没关系。MQL5 官方的 ONNX.Price.Prediction 项目自带训练脚本和 EA,可以直接看代码学。
能训练出什么类型的模型
别管技术名词。想想你让模型回答什么问题:
| 你的问题 | 模型干的事 | 输出什么 | 例子 |
|---|---|---|---|
| 下根 K 线涨还是跌? | 方向分类 | 涨/跌 + 概率 | XGBoost 分类器 |
| 收盘价大概多少? | 价格回归 | 一个价格数字 | LSTM 回归 |
| 现在是趋势还是震荡? | 状态分类 | 趋势/震荡/过渡 | CNN 模式检测 |
| 这个信号靠谱吗? | 信号过滤 | 可信度 0-100% | 在现有规则上加的噪音过滤器 |
| 接下来波动大不大? | 波动率预测 | 预期波动幅度 | GARCH + 神经网络混合 |
前两行最吸引眼球,但根据我们的经验,后三行才是 ONNX 模型真正好用的地方。下面会讲为什么。
这些类型可以叠加用。有的 EA 同时跑几个模型:一个判断市场状态,一个在对应状态下预测方向,一个根据预期波动率决定仓位大小。ONNX 格式对这些都一视同仁。
到底有没有用——说实话
看怎么用。我们把测过的 ONNX EA 分成三类。
确实有用的场景
信号过滤是最稳定的用法。你已经有一套基于规则的策略在出信号。ONNX 模型当第二意见:"这个信号置信度 78%,执行"vs"这个只有 34%,跳过"。它不需要预测未来,只需要区分好的信号和差的信号。这个问题比预测涨跌简单多了。
根据波动率调仓位是第二个赢面。模型预测下一个交易时段的价格波动幅度。EA 用这个数字调整手数:预期大波动就小仓,预期平静就正常仓。不需要预测方向,只预测幅度。学术研究显示即使方向预测一般,这个方法也能改善风险调整后的收益。
市场状态判断是第三个。不同策略适合不同行情。趋势策略在震荡市亏钱,震荡策略在突破市亏钱。如果 ONNX 模型能可靠地告诉你"现在是趋势状态",你可以切换策略参数。
不太靠谱的场景
纯方向预测做交易决策——大多数人期待 ONNX 在这发光,但这恰恰是效果最不稳定的用法。学术论文上 R² 0.96、准确率 75% 的数字是真的,在测试集上、在论文里。加上点差、滑点和变化的市场环境进入实盘,优势缩水很快。
一篇ML 算法交易的综合分析发现 Random Forest 和 SGD 在部分测试中跑赢了其他模型,但结论是:"没有任何单一策略在所有条件下都可靠。"均值回归策略在突破时崩溃,趋势策略在震荡时失效。ML 没有魔法解决"不同行情需要不同方法"这个根本问题。
危险的场景
过拟合模型配上完美回测曲线在卖。 ONNX 模型完全可以在历史数据上训练出一条漂亮的净值曲线。这不代表它未来能赚一分钱。如果卖家不展示 walk-forward 验证或样本外测试结果,你应该怀疑。我们专门写过回测和实盘结果的差距,因为被坑的人太多了。
训练数据泄露了未来信息。 如果训练过程中不小心用了交易时点不可能知道的数据(前视偏差),模型学会了"作弊"。回测好看得不得了,实盘就是随机的。这个错误出奇地容易犯,连有经验的开发者也会中招。
我们实际测到了什么
过去一年测 ONNX EA 的三个发现:
表现最好的不是最复杂的模型。一个调教好的 XGBoost 加上干净的特征工程,在我们测的几个品种上打赢了 deep LSTM。差别不在模型架构,在数据准备和训练/测试划分是不是严格执行。
信号过滤始终比纯预测好用。一个规则一般但加了好的 ONNX 过滤器的 EA,跑赢了没有规则纯靠预测模型的 EA。规则提供结构,模型提供筛选。
所有模型都会退化。开始表现好的,3-6 个月后需要重新训练。市场在变。一个用 2024 年数据训练的模型,不知道 2025 年末开始的波动率变化。如果你的 ONNX EA 没有重训练计划,它有保质期。
如果你想自己试
前提: 会基础 Python。理解过拟合是什么。接受第一个模型大概率不行。
最简单的起步: MQL5 官方的 ONNX.Price.Prediction 项目。自带训练脚本和 EA。打开 MetaEditor,在 Toolbox > Public Projects 里找到它,加入就行。
不想自己训练? 可以用别人训练好的模型。但你要知道,你在信任他们的训练过程、数据划分和验证方法。如果他们过拟合了,这个问题就成了你的。
这是系列文章的第三篇。前两篇:ONNX 正在改变 EA 开发方式和ONNX 和 ChatGPT 是两种完全不同的 AI。
最后一句话
ONNX 不神秘。它就是一个跑数学的文件。真正难的不是技术,是判断你的模型学到的是真实的市场规律,还是历史数据里的噪音。
技术不是门槛。训练纪律才是。
关于作者:FXTool 团队每天都在开发和测试 MetaTrader 交易工具。我们在实盘账户上运行每一款上架的 EA,并公开结果。本文来自我们开发 50+ 款 EA、服务数千名交易者的实战经验。